
This feature upgrade came directly from customer feedback. THANK YOU! We love hearing your ideas – please keep them coming!
When Protocol Designer (PD) was first created, Opentrons envisioned a platform where scientists could quickly build basic pipetting protocols without having to write any code. As PD became more utilized by our community, it became a tool allowing scientists to build lengthy and complex protocols that tackle applications like DNA extraction, protein purification, and COVID-19 diagnostics. When we started seeing scientists using PD to build protocols with 100+ steps, we knew we needed to offer them a better way to optimize and edit their protocols. Scientists have enough to worry about as it is: we don’t want them spending their time tediously changing the same settings over and over again.
So—we’ve just added batch-edit mode to PD! Users can now select, duplicate, delete, and edit multiple steps, enabling quicker iteration and optimization of scientific protocols.
Before the product development team even began thinking about how to get this feature done, we knew it would be a huge engineering challenge. Extending an app like PD to support an entirely different user flow like batch-edit would require heavy refactors that impact core parts of Protocol Designer. This post will focus on this feature from an engineering perspective, but I also want to call out the massive design challenge it was to get this done. One of the core tenets of PD is ease of use, and crafting an easy to use, intuitive, user experience to build and optimize complex scientific protocols is no mean feat.
PD was designed to build scientific protocols from the ground up, creating and editing steps one after another. The flow goes as follows:
1. User creates a step (transfer, mix, heat, etc.)
2. Fills out the relevant step information in a form (pipettes, labware, liquid volumes, etc.)
3. Saves the form
4. Creates the next step
5. Etc.

This means that at any given time, the main “design” tab in PD displays some/all of the following:
1. A list of all of the steps in the protocol
2. A visual snapshot of a particular step of a protocol
3. A form for the user to fill out to specify what the step should do
PD’s UI components (built in React) and global state management store (implemented in Redux) were built to accommodate this user flow. This means that PD’s redux store keeps track of things like a “selected step” so users can visualize what’s actually happening at a specific part of their protocol. It also keeps track of things like an “unsaved form”, which tracks pending changes before they get committed.
Notice the singular nature of the data captured above (selected step, unsaved form). PD’s redux store and React components were built to interact with one step, not multiple. To illustrate this point, let’s look at how PD fills in the wells on a piece of labware according to which step is selected (this is how the wells appear green in the image above).
1. A user clicks on a step
2. A redux action called “SELECT_STEP” gets dispatched, updating the “selected item” reducer
3. A redux selector that listens for changes to the “selected item” will search for the labware and wells that are being used in that specific step
4. The well information will be passed into a component called “LabwareRender” which will then use that information to shade in the wells
But what happens when we start keeping track of multiple selected steps instead of just one? In particular, what happens to step 3 above? If we have more than one selected item, what do we do?
In order to prevent our components from breaking when multiple steps get selected/edited at the same time, we had to make core changes to how we represent and translate our data. Let’s walk through what we did.
Prior to this feature, we only kept track of a single “selectedItem” in our redux store. Our “selectedItem” reducer type interface looked something like the snippet below. Note, all code snippets in this post are in JavaScript and typed with flow js.
| Type SelectableItem = SingleSelectedItem const selectedItem = (state: SelectItemState, action: SelectedItemAction): ?SelectableItem |
The reducer function “selectedItem” accepts state and an action, and returns the selected item (an object that holds relevant information about the selected item), or null if there is no selected item.
To avoid adding a new reducer to hold multiple steps while in batch-edit mode, we opted to modify the “selectedItem” reducer to accommodate returning both single and multiple steps.
| Type SelectableItem = SingleSelectedItem | MultipleSelectedItem const selectedItem = (state: SelectItemState, action: SelectedItemAction): ?SelectableItem |
The return type of “selectedItem” was modified to be able to hold an object that will contain a single step id (representing a single selection type), or an object that will contain a list of multiple step ids (representing a multiple selection type). In order to tell redux that we have selected multiple steps, we created an action called “SELECT_MULTIPLE_STEPS”, which the “selectedItem” reducer function will accept, and update its value to represent multiple steps (see type “MultipleSelectedItem”)
There is certainly some awkwardness in a reducer named “selectedItem” that might hold data representing more than one item, but we ultimately decided the tradeoff was worth not having to add an additional reducer to represent multiple selected items, thereby having to null out one or the other when switching between single and batch-edit mode.
To prevent components that were used to accepting just one step as props from breaking, we were able to leverage the redux selector pattern to transform data from our reducers into a format that our components can accept. The main selector that feeds information about the selected step into our components is called “getSelectedStepId”, and it used to do something along the lines of this:
| const getSelectedStepId: ?string = (state: State) => state.selectedItem |
This is a simplification of what the selector used to do, but you get the idea — it basically reaches into the “selectedStep” reducer and returns whatever is in there. Because our components get the selected step from the selector instead of the reducer, we’re able to first translate the data held in the reducer before it gets fed into our components.
This meant that all we had to do was modify “getSelectedStepId” to return a step id if the reducer holds a “single selection type”, and null otherwise:
| const getSelectedStepId: ?string = (state: State) => state.selectedItem.selectionType === SINGLE_STEP_SELECTION_TYPE ? state.selectedItem.id : null |
With our existing components now being able to deal with multiple steps being selected, we added a new selector called “getMultiSelectItemIds” that is similar to “getSelectedStepId”, but returns a list of step ids when in batch-edit mode, and null otherwise. This selector will be used to tell PD which steps are selected in batch-edit mode.
| const getMultiSelectItemIds: ?Array<string> = (state: State) => state.selectedItem.selectionType === MULTI_STEP_SELECTION_TYPE ? state.selectedItem.ids : null |
Having our data flow from reducers => selectors => components really helped us here, because we were able to change the structure of our reducers without having to be concerned about our components breaking. In addition, because we compose our selectors on top of each other using reselect, all of the higher order selectors that use “getSelectedStepId” continued to work just fine.
PD determines which fields across multiple steps are editable based on a matrix of rules. For example, if a user selects two transfer steps, and the two steps have different pipettes, they should not be able to modify the shared pipette flow rate settings between the two steps.
Using the rule matrix, we created another redux selector called “getMultiSelectDisabledFields”, which as the name suggests, determines which fields should be disabled in multi-select mode. It iterates through all of the fields in the selected forms, and determines whether the forms share the same pipettes, labware, etc. Depending on the rule for each field, it will return a map of which fields are disabled along with the reason why each field is disabled. The batch-edit form component can then use this information to populate which fields are editable, and which are not.
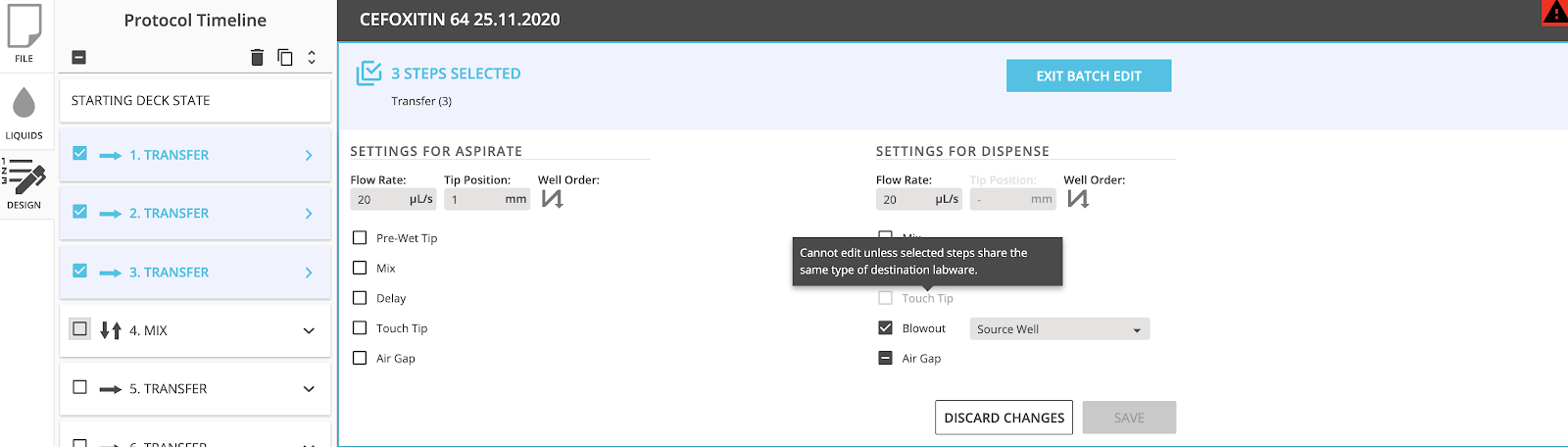
Once the batch-edit form’s fields are populated, changes to their values need to get tracked as users modify them. This is for a few reasons:
1. We need to know whether a user has made any changes to the form, because if they have, we want to alert them that they’ll lose those changes if they try to exit the form.
2. Once they finish making their changes, we need to merge the unsaved changes they made (affecting multiple steps) into the saved map of steps inside of PD’s global state.
For single-edit mode there is another reducer called “unsavedForm” which holds all of the information in a single unsaved form, but we decided not to reuse it for batch-edit mode because:
1. The batch-edit form holds information across multiple forms, not just one
2. In batch-edit mode it is far more useful to only hold information about which form fields have been changed. This way when a user saves the batch-edit form all we have to do is spread the changes into each of the affected steps in our “savedStepForms” reducer that holds all of the saved form information. This also means that whenever the object representing the changes is not empty, we know the user has made changes.
To accomplish this, we created a new reducer called “batchEditFormChanges”, which holds a plain JavaScript object representing the edited field names as keys, along with the associated field values.
PD’s form components are “smart” in that they are connected to redux so they can access form data. The issue is that the logic in the “smart” components is directly tied to single-edit mode. In order to remove single-edit mode dependencies, we decided to inject form components in both single-edit mode and batch-edit mode with a set of props that share a common API called “FieldProps”
| export type FieldProps = {| disabled: boolean, errorToShow: ?string, isIndeterminate?: boolean, name: string, onFieldBlur: () => mixed, onFieldFocus: () => mixed, tooltipContent?: ?string, updateValue: mixed => void, value: mixed, |} |
To accomplish this, we created two separate functions (one for single-edit mode and one for batch-edit mode) that are responsible for computing each of the “FieldProps” above. They are aptly named “makeSingleEditFieldProps” and “makeBatchEditFieldProps”. The main parent component for the single-edit form uses the former, and counterpart for the batch-edit form uses the latter.
Both of these pure functions take the corresponding single-edit/batch-edit state information (like what information is held in each form), perform the necessary logic, and return an object that holds the same “FieldProps” interface as above. This means that as long as all of our form components accept the “FieldProps” interface, they can be used for both single-edit mode and batch-edit mode.
It was quite a bit of work migrating our existing form components away from the coupled single-edit mode logic (and we still have more left to finish), but creating this common props interface allowed us reuse our existing form field components, while drawing a clear line between single-edit mode logic and batch-edit mode logic.
All of the work described above (and more) took our team of three engineers, one designer, one product manager, and one QA engineer about three months to complete. You can see our epic for selecting multiple steps here, and our epic for batch-edit form specific work here. All of our work is open source, so feel free to poke around our codebase.
Before we began developing this feature, we asked ourselves if the investment of an entire quarter was worth it. Since batch-edit has been by far the most common feature request coming from our users, we ultimately decided it was. However, it’s worth noting that the reason users want to edit multiple steps at the same time is because their protocols often consist of many steps that are easier to edit in bulk rather than one at a time. As more and more scientists use PD to tackle more and more complex problems, the issue of protocols holding many steps will increase.
Looking ahead, we’d like to better understand what exactly users are building with PD, and what we can do to help them minimize the steps they have to create. As PD continues to grow and evolve, we’ll be hard at work answering these questions. While we are very excited about this feature, our mission to empower scientists to move faster, and to solve the problems we desperately need them to, is far from over.



















































